sklearn 学习笔记-1
一、简单介绍
sklearn库是Python中自带的开源机器学习库,全称scikit-learn。 基于Numpy、SciPy、Matplotlib等数值计算库实现高效应用, 包括了大部分主流的机器学习算法。
官网链接: [scikit-learn](scikit-learn: machine learning in Python — scikit-learn 1.3.0 documentation)
当然在此之前最好弄清楚机器学习和深度学习的区别,sklearn并不是做深度学习的。
sklearn的基本模块介绍(来自官网+个人翻译):
分类Classification:识别某个对象属于哪个类别。常见的应用有:垃圾邮件识别、图像识别。
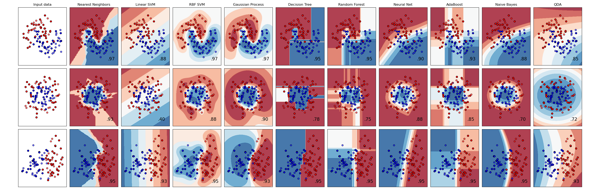
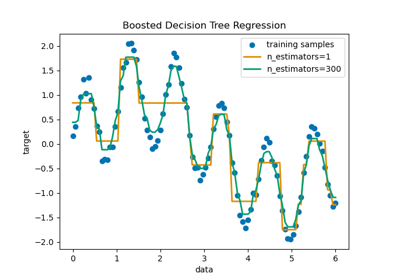
回归Regression:预测与对象相关联的连续值属性。常见的应用有:药物反应,预测股价。
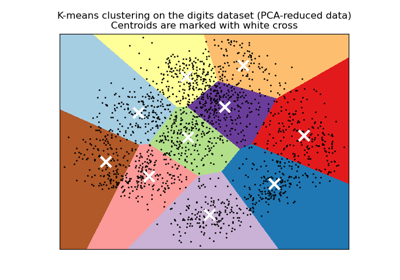
聚类Clustering:将相似对象自动分组。常见的应用有:客户细分,分组实验结果。
降维Dimensionality reduction:减少要考虑的随机变量的数量。常见的应用有:可视化,提高效率。
模型选择Model selection:比较,验证,选择参数和模型。它的目标是通过参数调整提高精度。
预处理Preprocessing:特征提取和归一化。 常见的应用有:把输入数据(如文本)转换为机器学习算法可用的数据。
二、安装过程
因为我有Anaconda 所以直接输入指令
1
| conda install scikit-learn
|
pip有的时候还是太烂了
三、鸢尾花Iris数据集测试
介绍
鸢尾花数据集iris是sklearn里自带的一个数据集之一,存储在sklearn.datasets里,调用方式非常简单如下
1
2
3
|
from sklearn import datasets
iris = datasets.load_iris()
|
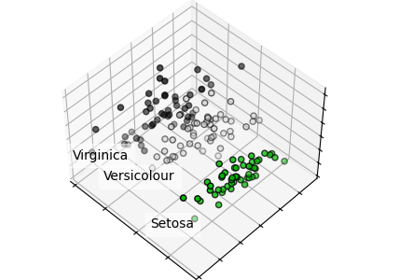
Iris数据集是常用的分类实验数据集,由Fisher, 1936收集整理。Iris也称鸢尾花卉数据集,是一类多重变量分析的数据集。数据集包含150个数据样本,分为3类,每类50个数据,每个数据包含4个属性。
选自"百度百科–IRIS"
综上所述,iris基本上是根据花的不同特征进行了一些记录和汇总,我们可以利用以下代码输出feature_names和target_names
1
2
3
|
print(iris.feature_names)
print(iris.target_names)
|
结果如下:
1
2
3
4
| ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
['setosa' 'versicolor' 'virginica']
|
输出iris的数据集大小
1
2
3
|
print(iris.data.shape)
print(iris.target.shape)
|
结果如下:
可通过以下html代码直观展示iris数据集
1
| <iframe src=http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data width=300 height=200></iframe>
|
iris数据集的图像化表示
1
2
3
4
5
6
7
8
9
10
11
12
13
|
X = iris.data
y = iris.target
import matplotlib.pyplot as plt
X_sepal = X[:, :2]
plt.scatter(X_sepal[:, 0], X_sepal[:, 1], c = y)
plt.xlabel("Sepal length")
plt.ylabel("Sepal width")
plt.show()
|
结果

测试KNN分类器
Examples:
这里采用了官网的源代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
|
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.colors import ListedColormap
from sklearn import datasets, neighbors
from sklearn.inspection import DecisionBoundaryDisplay
n_neighbors = 15
iris = datasets.load_iris()
X = iris.data[:, :2]
y = iris.target
cmap_light = ListedColormap(["orange", "cyan", "cornflowerblue"])
cmap_bold = ["darkorange", "c", "darkblue"]
for weights in ["uniform", "distance"]:
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
_, ax = plt.subplots()
DecisionBoundaryDisplay.from_estimator(
clf,
X,
cmap=cmap_light,
ax=ax,
response_method="predict",
plot_method="pcolormesh",
xlabel=iris.feature_names[0],
ylabel=iris.feature_names[1],
shading="auto",
)
sns.scatterplot(
x=X[:, 0],
y=X[:, 1],
hue=iris.target_names[y],
palette=cmap_bold,
alpha=1.0,
edgecolor="black",
)
plt.title(
"3-Class classification (k = %i, weights = '%s')" % (n_neighbors, weights)
)
plt.show()
|
输出结果:
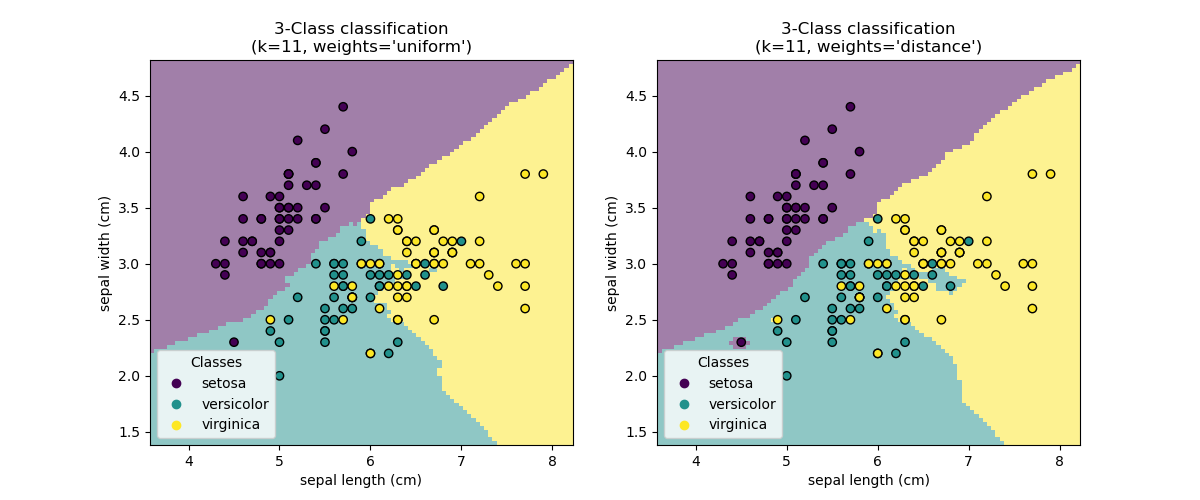

感觉多少有点不准
注:p范数
∣∣X−Y∣∣p=(Σi=1n∣xi−yi∣p)p1
四、wine葡萄酒数据集
介绍
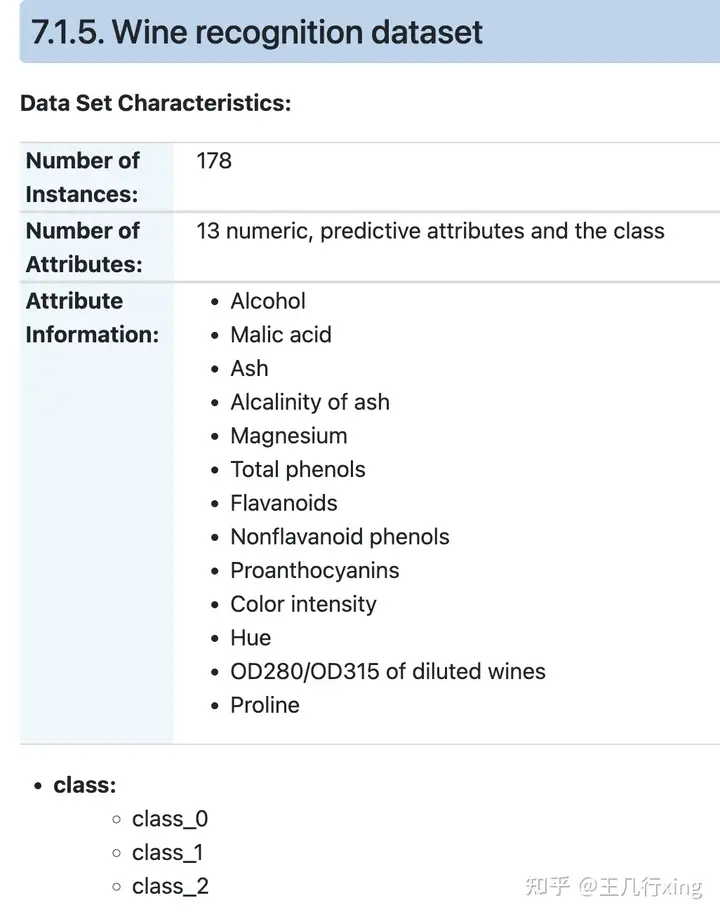
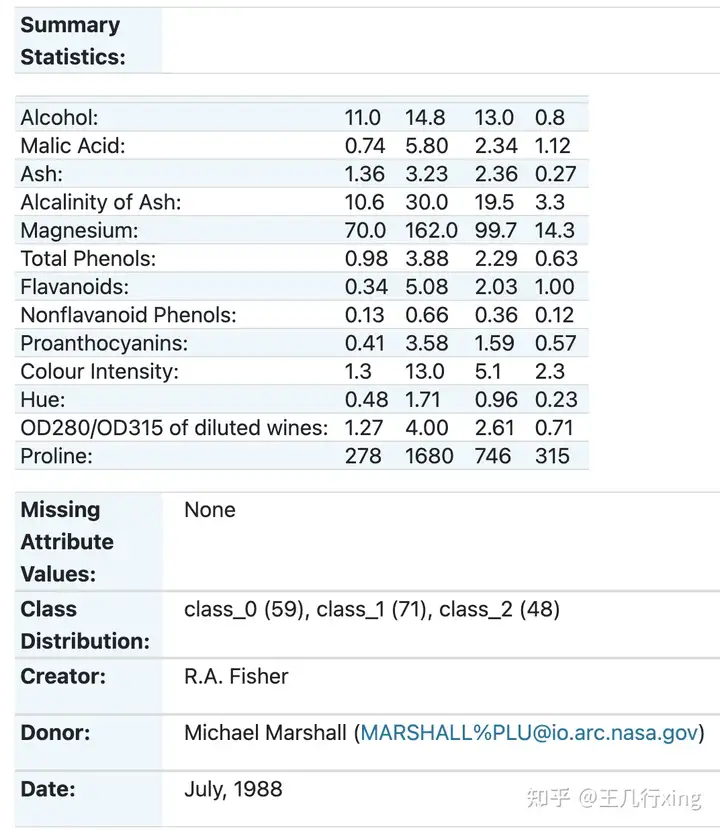
葡萄酒识别数据集(Wine Recognition dataset)通常用于多类别分类问题建模。数据集包括从三个不同的品种(类别)的葡萄酒中测得的13种不同的化学特征,共178个样本。这些化学特征包括酸度、灰分、酒精浓度等。
测试KNN分类器
在iris分类的基础上略微改动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.colors import ListedColormap
from sklearn import datasets, neighbors
from sklearn.inspection import DecisionBoundaryDisplay
n_neighbors = 15
wine = datasets.load_wine()
X = wine.data[:, :2]
y = wine.target
cmap_light = ListedColormap(["orange", "cyan", "cornflowerblue"])
cmap_bold = ["darkorange", "c", "darkblue"]
for weights in ["uniform", "distance"]:
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X, y)
_, ax = plt.subplots()
DecisionBoundaryDisplay.from_estimator(
clf,
X,
cmap=cmap_light,
ax=ax,
response_method="predict",
plot_method="pcolormesh",
xlabel=wine.feature_names[0],
ylabel=wine.feature_names[1],
shading="auto",
)
sns.scatterplot(
x=X[:, 0],
y=X[:, 1],
hue=wine.target_names[y],
palette=cmap_bold,
alpha=1.0,
edgecolor="black",
)
plt.title(
"3-Class classification (k = %i, weights = '%s')" % (n_neighbors, weights)
)
plt.show()
|
结果如下:


感觉还是不太行
五、评价
sklearn在小数据集toy datasets上起到一个实验的价值,可实际上过于小的数据集没有分析的价值,下一步要考虑在更大的数据集上做分类- 现在的调参手段还不足,需要网格调参并且对不同参数的结果有明确的评价指标
- 其他
